大模型训练2:TPU是如何工作的?
今天主要来讲一讲 TPU 是怎么工作的,它们之间是如何联网的,从而支持多芯片的训练和推理。这些结构和机制会直接影响你常用算法的性能表现。当然,即使你是用 GPU 的,也有很多有用的内容值得参考。
什么是 TPU?
TPU 本质上就是一个专为矩阵乘法设计的计算核心(叫做 TensorCore),旁边挂着一块超快的内存(叫 HBM,高带宽内存)。可以把它理解成一台超强的“矩阵乘法专用机”,不过它还有一些其他关键功能。
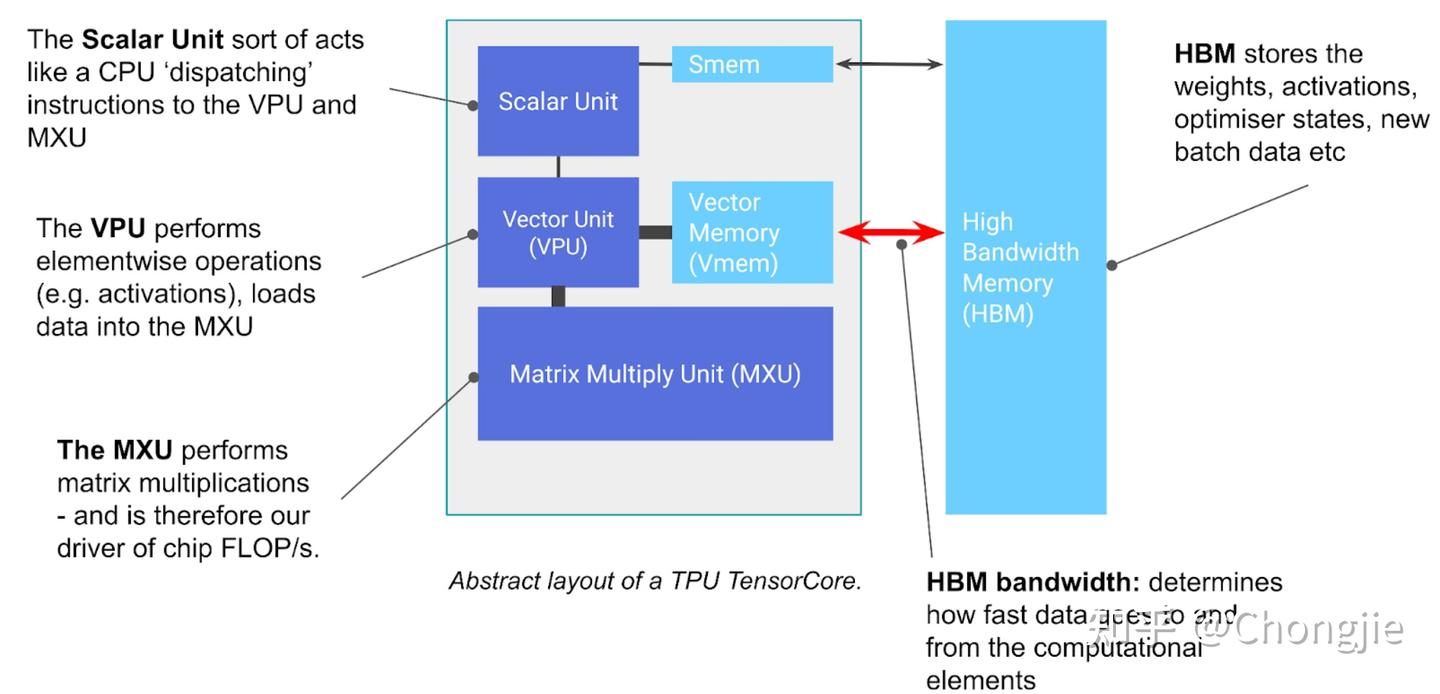
TensorCore 主要包含三个重要单元:
- MXU(矩阵乘法单元,Matrix Multiply Unit):这是整个 TensorCore 的核心。以 TPU v5e 为例,它每 8 个周期就能完成一次 bfloat16 [8, 128] × bfloat16 [128, 128] → float32 [8, 128] 的矩阵乘法,靠的是所谓的 systolic array 结构。在 1.5GHz 下,单个 MXU 每秒能跑约 5e13 次 bfloat16 运算。大多数 TensorCore 会配备 2 或 4 个 MXU,比如 TPU v5e 的总 FLOPs(bfloat16)就是 2e14。此外 TPU 还支持更低精度的矩阵乘法,比如 int8,可以达到更高的吞吐量(v5e 是 4e14 ops/s)。
- VPU(向量处理单元,Vector Processing Unit):负责执行常见的数学操作,比如 ReLU 激活、点乘、加法、向量间的逐元素操作等。比如你要对一个张量做求和归一化这种事,也是在这里完成的。
- VMEM(向量内存,Vector Memory):这是一块片上小内存,就挨着计算单元。虽然容量比 HBM 小得多(比如 v5e 是 128MiB),但访问速度非常快。它有点像 CPU 里的 L1/L2 缓存,但更大、而且由程序员手动控制。注意:TensorCore 不能直接从 HBM 读取数据做计算,数据必须先搬进 VMEM 才行。
一句话总结:TPU 是专为深度学习设计的“矩阵加速器”,核心思想就是用超强的矩阵乘法引擎 + 超快的数据通路(VMEM + HBM)来提升训练速度。
TPU 的强项就是矩阵乘法,而且是真的非常非常快。比如目前最强的 TPU 之一 —— TPU v5p,每个核心每秒可以跑 2.5e14 次 bfloat16 运算,一个芯片就是 5e14 次。如果你拿一个拥有 8960 颗芯片的大型 TPU pod 来算,一秒能跑 4 exaFLOPs,已经是世界级的超级计算机级别了,而且 Google 手上有很多这样的 pod。
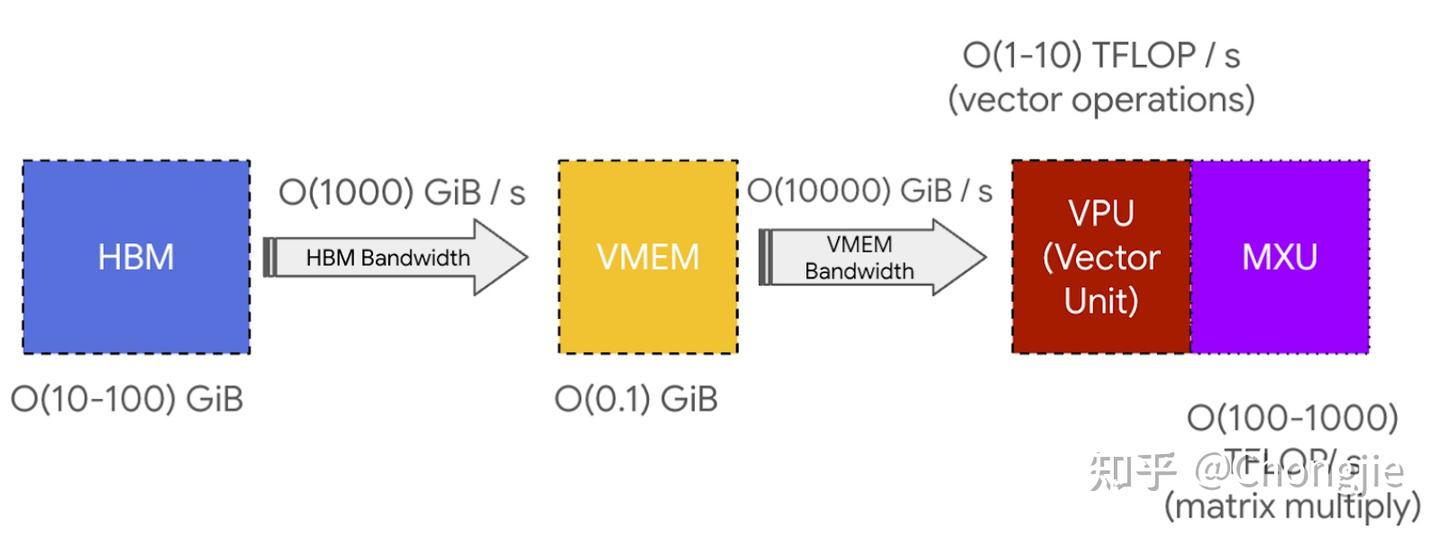
上面那张图还标了 SMEM 和 scalar unit,主要用来处理控制流相关的逻辑(比如 if-else、for loop),你不用特别关注,但有个重要的组件你一定要搞清楚:HBM(高带宽内存),这就是 TPU 存数据的地方,用来存张量。它的容量通常是几十 GB,比如 TPU v5e 是 16 GiB。每次你做计算的时候,数据都会从 HBM 通过VMEM(片上缓存)先搬到计算核心 MXU,然后计算完成后再从 VMEM 把结果写回 HBM。HBM 和 TensorCore 之间的带宽(就是通过 VMEM 通道的速度)通常是 1~2 TB/s,这个带宽是限制内存密集型任务计算速度的关键瓶颈,所以常被称为 HBM 带宽。
不过别担心,TPU 在设计上是很智能的 —— 所有操作都是 流水线式并行处理。举个例子,要做矩阵乘法 Y = X @ A,TPU 会:
- 先把部分的 X 和 A 从 HBM 搬到 VMEM;
- 然后把 VMEM 里的数据喂给 MXU 来做乘法(比如 X 是 8×128 块,A 是 128×128 块);
- 然后把乘好的结果块再写回 HBM。
而这一整套过程是分阶段交叉进行的,比如:
- 在计算当前一块的时候,就已经在搬下一块进 VMEM;
- 计算完当前一块的时候,也在把之前算好的结果写回 HBM。
通过这种“搬 + 算 + 写”三管齐下的流水线策略,TPU 能够最大程度保证 MXU 时刻有活干,避免它闲着等内存,从而维持计算瓶颈(compute-bound)状态,而不是被内存拖慢(memory-bound)。TPU 之所以能打,就是靠 MXU 算得快、HBM 送得快、VMEM 做缓存中转,再加上流水线式调度,几乎把硬件压榨到了极致。
矩阵乘法(matmul)的数据流动路径其实和普通的点操作差不多,唯一的不同是它加载到的是 MXU,而不是 VPU。另外,由于同一块权重会被多个输入激活块反复使用,所以 matmul 的加载顺序也和点操作不同。你可以想象是:数据从 HBM 流入 VMEM,再进到 VREGs(向量寄存器),然后喂给向量单元或矩阵乘单元(VPU 或 MXU),最后结果再从 VMEM 写回到 HBM。但问题是:如果 HBM → VMEM 的速度跟不上计算单元(VPU/MXU) 的吞吐能力,那计算单元就“饿了”,得不到足够的数据,就浪费了计算力,这种情况叫“带宽瓶颈”(bandwidth-bound)。
重点总结一下
TPU 架构很简单:先把数据从 HBM 拉到 VMEM;然后 VMEM 把数据喂给 systolic array(一个高效做乘加的阵列);每秒能跑 200 万亿次乘加(200 TFLOPs);HBM ↔ VMEM 和 VMEM ↔ MXU 的带宽,决定了你的程序到底能跑多快。
VMEM 与 Arithmetic Intensity 的关系
虽然 VMEM 容量比 HBM 小很多,但带宽高得多(大概是 HBM 的 22 倍),这意味着:如果你能把所有的输入和输出都装进 VMEM,就大大降低了通信瓶颈;特别是当一个算法的 arithmetic intensity 本来就不高时(就是 FLOPs 比 byte 少的那种),只要能放进 VMEM,就还有可能跑得快。举个例子:在 HBM 中你可能需要每 byte 至少算 200 次才能不浪费资源,而在 VMEM 中只要算 10~20 次就够了。所以,如果你能把参数提前放进 VMEM,你就能用很小的 batch size 就达成高效率。问题是 VMEM 太小了,很多模型根本塞不下,这才是挑战。
TPU 芯片和组网结构
一个 TPU 芯片通常有两个核心,共享内存,一起工作就叫做 megacore,从 TPU v4 开始都是这样。早期(v3 及以前)是两个独立核心,各自有自己的内存;面向推理的 TPU(如 v5e)只有一个核心,不搞共享。
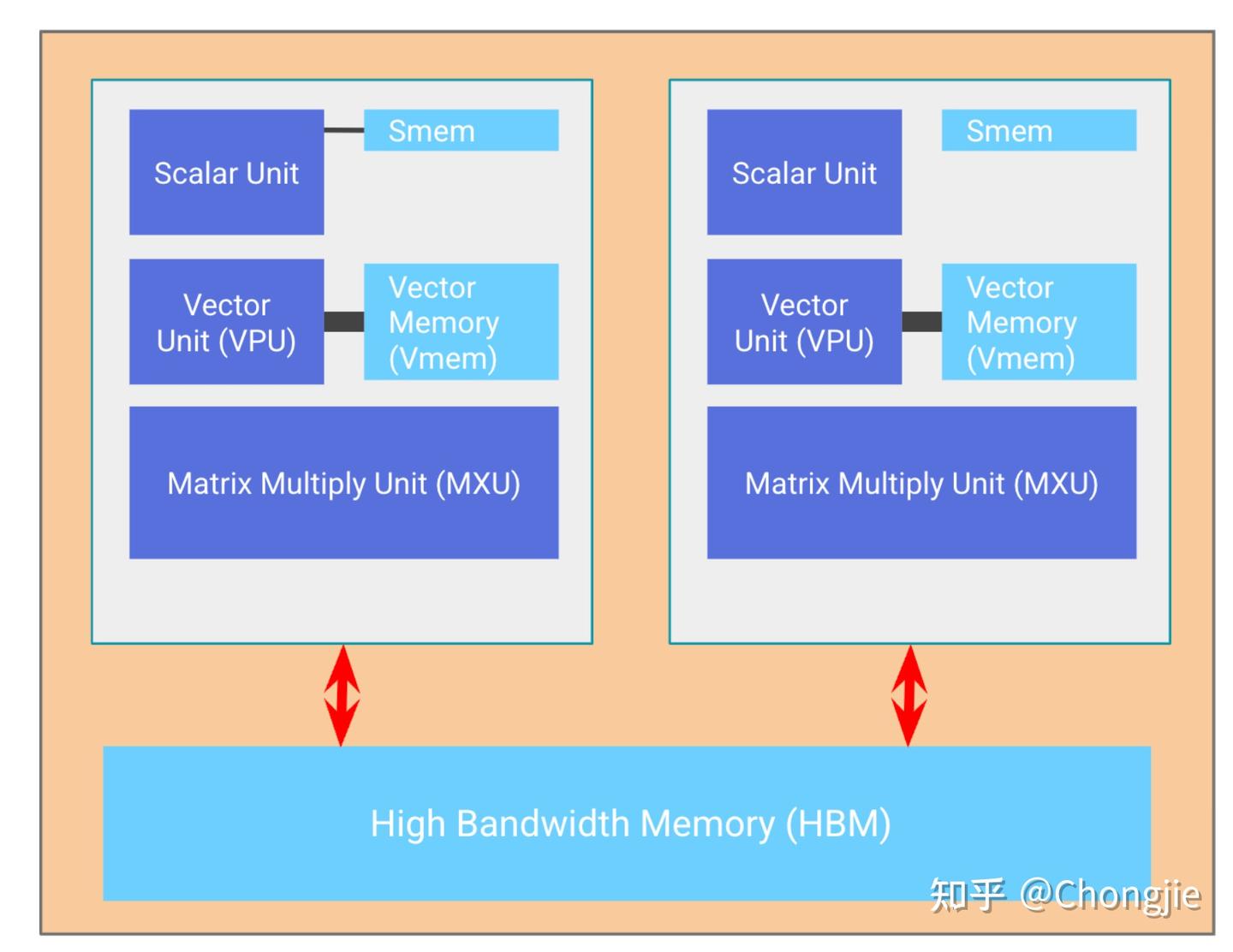
4 个芯片组成一个 tray(托盘),通过 PCIe 网络连到一个 CPU 主机,很多熟悉 Google Colab 或 TPU VM 的用户看到的就是这种 4 芯片、8 核心配置。推理版的 TPU v5e 是 2 个托盘一个主机,但每芯片只有 1 个核心,所以是 8 芯片 8 核心。
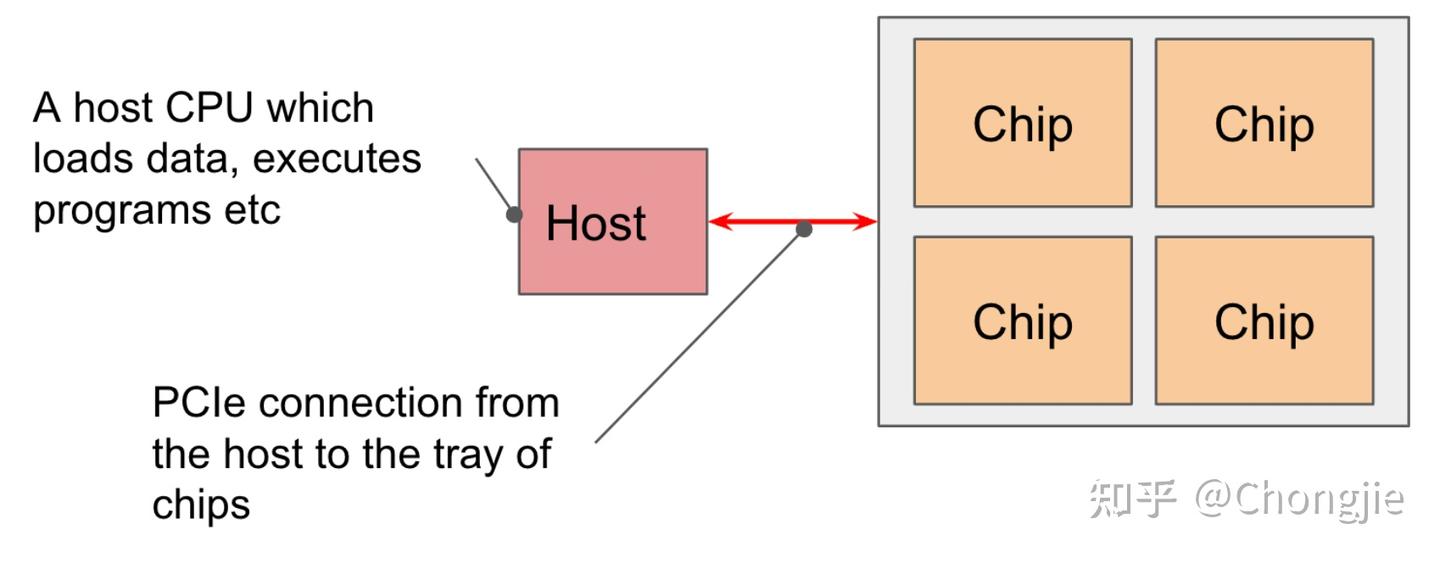
不过PCIe 是个限制项:和 HBM ↔ VMEM 一样,CPU ↔ HBM 之间通过 PCIe 连接,它也有带宽限制。比如 TPU v4 的 PCIe 带宽只有 16GB/s(单向),比 HBM 慢了快 100 倍;所以虽然你可以从主机内存搬数据进 TPU,但速度慢得很,不适合频繁交换。
TPU 网络结构
TPU 芯片之间通过叫做 ICI 网络(Inter-Chip Interconnect) 的通道连接起来。在一个 TPU Pod 中,不同芯片直接用 ICI 连着,不需要经过主机(host),效率非常高。对于老一代 TPU(v2 / v3) 、推理芯片(v5e)以及 v6e(Trillium),每个芯片跟4 个最近的邻居连接,构成一个 2D 环形网络(2D torus),两端用“边缘连接”封住,组成环。对于 TPU v4 / v5p,每个芯片和 6 个邻居连接,组成一个 3D 环形网络(3D torus);
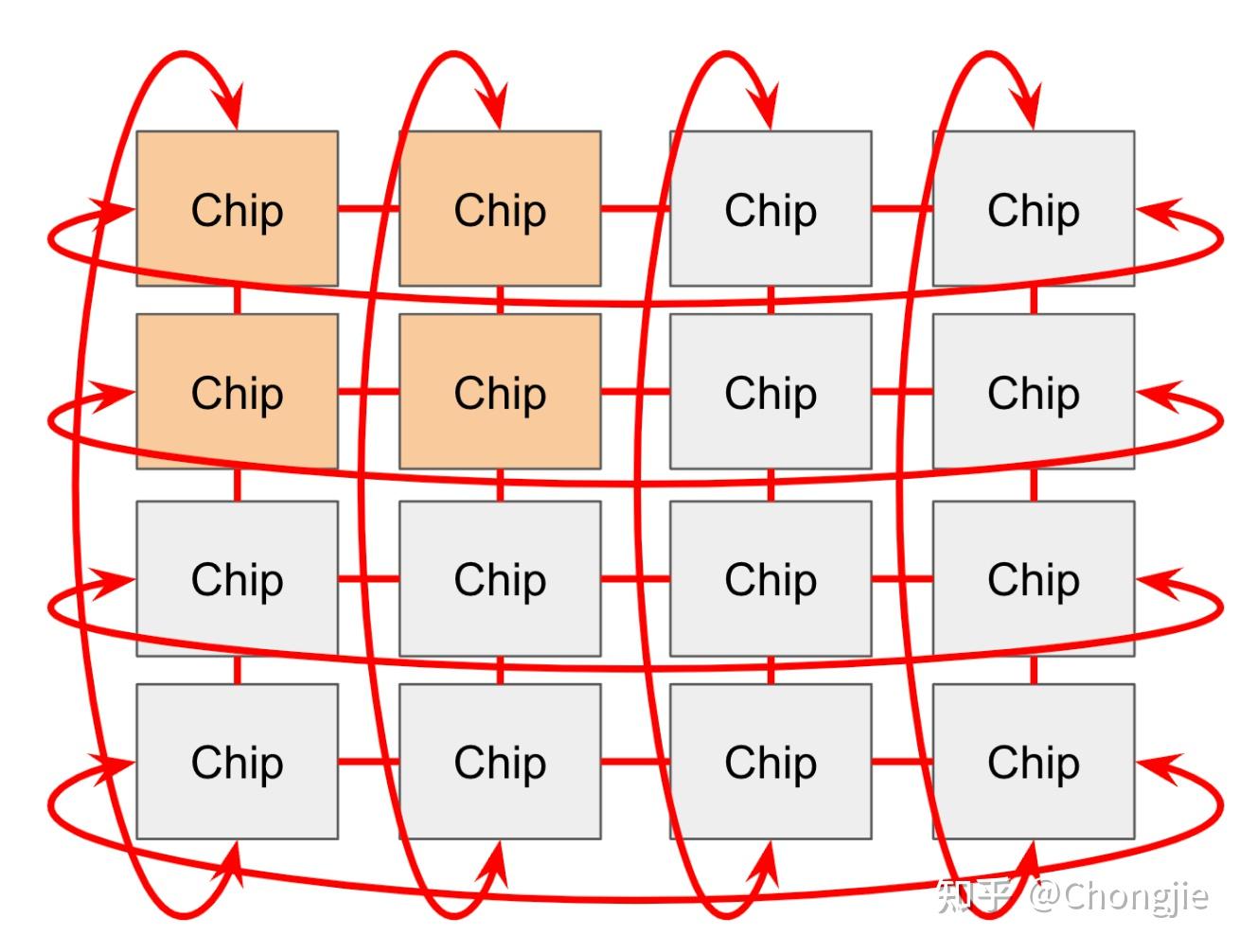
这种“环形结构(Torus)”的好处是把任意两个芯片之间的最远距离从 N 缩短到了 N/2,数据传输更快、更稳定。有些网络还用了所谓的 “扭曲环 Mobius” 结构,类似莫比乌斯带,进一步减少了芯片间的平均通信距离(这太 geek 了,有兴趣可以自己搜图)。
TPU Pod 和 SuperPod
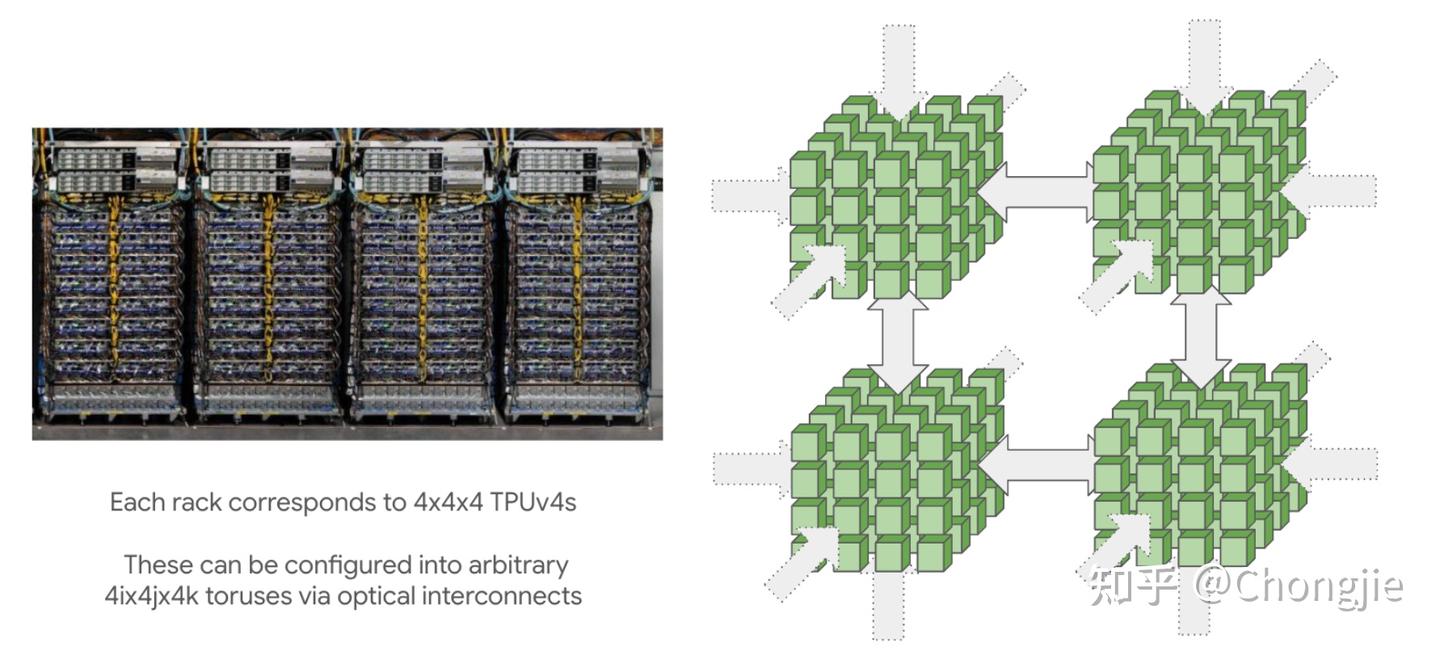
TPU 是按 “Pod” 来组的,Pod 内部通过 ICI 连接。Pod 可以特别大,比如 TPU v4 的最大 Pod 是 16×16×16 个芯片,TPU v5p 最大可以达到 16×20×28。这么大的网络其实是通过 4×4×4 的芯片小方块连接而成,中间用光学交换器做 “wraparound” 连起来(有点像包裹起来的立方体)。这些方块可以重新配置,实现灵活的超大规模拓扑结构。
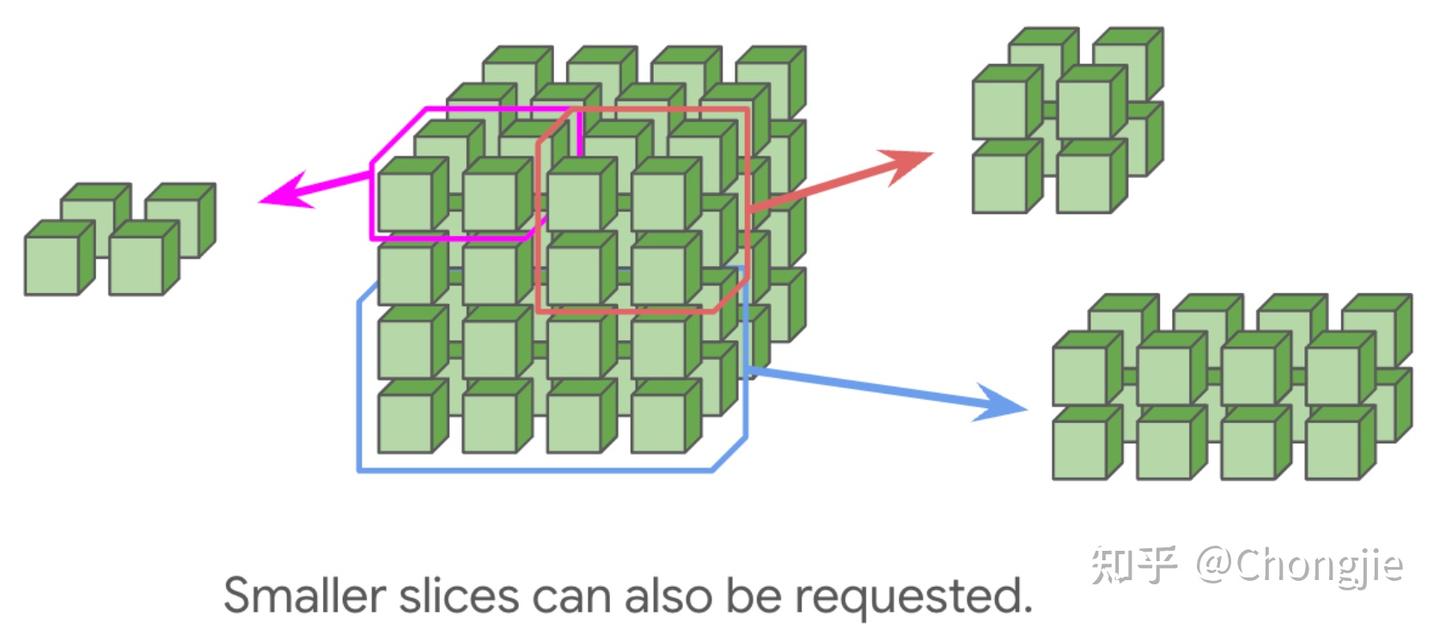
你也可以请求一个小规模拓扑,比如 2×2×1、2×2×2,但这种小拓扑没 wraparound,通信效率就低了。没有 wraparound 的情况下,通信延迟通常会翻倍,所以建议尽量选 4×4×4 或它的倍数这种有 wrap 的结构。
对于TPU v5e 和 Trillium(v6e),它们是专门为推理优化的,构成一个 16×16 的 2D torus;只要某一维有 16,就会自动有 wraparound,不支持超出 16×16 的拓展。但可以通过 DCN(Data Center Network) 实现跨 Pod 通信,DCN 是 主机 ↔ 主机 的通道,速度比 ICI 慢多了。
TPU 和 GPU 在连接方式上有挺大的差别。TPU 是那种“邻居互联”的风格,每个芯片只连它周围的几个芯片,像搭积木一样拼成一个二维或三维的“环形网络”(torus)。这种连接方式很简单、便宜,而且扩展性特别好。相比之下,GPU 用的是一套更复杂的“全连接近似”结构,靠一堆 NVLink 交换机把所有 GPU 尽可能都连起来。这样做虽然让同一个节点里的 GPU(比如一台 8 卡的 H100 机器)之间通信特别快,但一旦规模上去,通信就得走好几级交换路径,延迟和成本都会飙升。
TPU 的思路就不一样了:它把每个芯片之间的通信带宽和连接数都固定下来,这样整个系统搭建起来既便宜又统一,比如 TPU v5p 每个芯片的 HBM 带宽有 2.5TB/s,芯片之间的 ICI 链路大概每个方向 90GB/s,而真正跨主机通信的 DCN(数据中心网络)只有可怜的 25GB/s。更关键的是,一个主机通常带 8 个 TPU 芯片,所以平摊下来,每个芯片能用的 DCN 带宽其实只有 3GB/s 出头,远远不如 ICI,更别提 HBM 了。
这就导致一个问题:如果你把模型切分到多个 TPU 芯片上运行,尤其是分布在不同主机上的时候,如果通信规划不好,很容易卡在带宽不够这件事上。特别是在“multi-slice”这种跨多个 TPU 分组训练的场景下,一组 ICI 相连的 TPU 叫做一个 slice,slice 之间的通信必须走 DCN。而 DCN 这条路非常绕:数据得先从 TPU 走 PCIe 到主机,再通过网络发出去,到了目标主机后再走 PCIe 写进目标 TPU 的 HBM,整个流程特别慢。所以训练时最理想的方式,是尽量把大部分通信压在 ICI 这一层,避免走 DCN 这条“慢车道”。这样才能让 TPU 的矩阵乘法单元(MXU)不被通信拖后腿,真正跑满算力。
经典总结
好了,晦涩的文字到此结束,总结一下:
TPU 本质上就是一个特别强的“矩阵乘法机器”,它连着三样东西:超快的内存(HBM)、周围几个“邻居芯片”(通过 ICI)、还有数据中心里其他机器(通过 DCN)。
这三种通信通道的速度从快到慢分别是:
- HBM 带宽:就是 TensorCore 和它本地内存之间的传输,非常快;
- ICI 带宽:芯片之间的通信,比 HBM 慢一点,但还挺快的;
- PCIe 带宽:主机和芯片托盘之间的连接,速度一般;
- DCN 带宽:多个主机之间通过数据中心网络通信,最慢。
在一个 slice 里(也就是一组 ICI 相连的 TPU),芯片之间只跟最邻近的芯片连接。如果你要让两个距离远的芯片通信,它们得一跳一跳地转发,挺费时间的。
此外,做矩阵乘法的时候,权重矩阵的两个维度最小都得填充到 128(TPU v6 上是 256),这样才能把 MXU(矩阵乘单元)用满。
还有一点是:精度越低,运算越快。TPU 支持 int8 和 int4,这比用 bfloat16 快两倍甚至四倍。当然啦,VPU(向量处理器)做的那些操作,比如激活函数啥的,还是用 fp32。
最后一条也很关键:为了不让 TPU 的算力闲着,我们得让不同通信通道上的数据量跟它们各自的速度匹配上。也就是说:快的通道多跑点,慢的通道少跑点,不然就拖后腿了。