Weight Spectra Induced Efficient Model Adaptation
May 29, 2025· ,,,,,,,·
0 min read
,,,,,,,·
0 min read
Chongjie Si
Xuankun Yang
Muqing Liu
Yadao Wang
Xiaokang Yang
Wenbo Su
Bo Zheng
Wei Shen
 Observation
ObservationAbstract
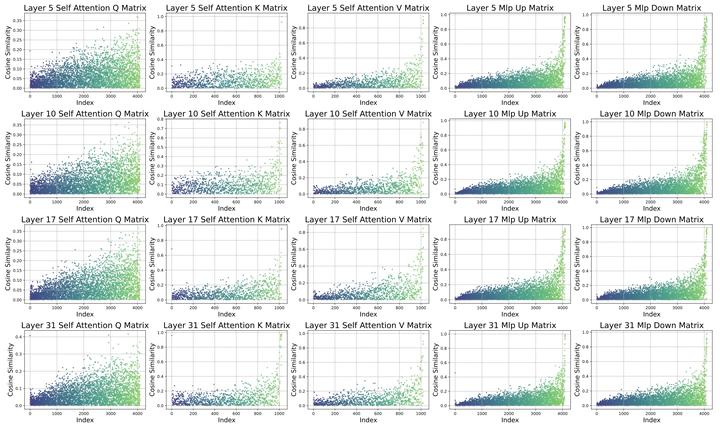
Large-scale foundation models have demonstrated remarkable versatility across a wide range of downstream tasks. However, fully fine-tuning these models incurs prohibitive computational costs, motivating the development of Parameter-Efficient Fine-Tuning (PEFT) methods such as LoRA, which introduces low-rank updates to pre-trained weights. Despite their empirical success, the underlying mechanisms by which PEFT modifies model parameters remain underexplored. In this work, we present a systematic investigation into the structural changes of weight matrices during fully fine-tuning. Through singular value decomposition (SVD), we reveal that fine-tuning predominantly amplifies the top singular values while leaving the remainder largely intact, suggesting that task-specific knowledge is injected into a low-dimensional subspace. Furthermore, we find that the dominant singular vectors are reoriented in task-specific directions, whereas the non-dominant subspace remains stable. Building on these insights, we propose a novel method that leverages learnable rescaling of top singular directions, enabling precise modulation of the most influential components without disrupting the global structure. Our approach achieves consistent improvements over strong baselines across multiple tasks, highlighting the efficacy of structurally informed fine-tuning.
Type
{kind=link}